So if you read the last part of this work you might be wondering how was the error less in the approximated solution than the proper implementation?
This comes down to simply exploiting the rules and expectations of the user. The user has selected to use 'float' as the base accuracy for the circle. This is usually done for performance reasons. Sin/Cos in float is cheaper than Sin/Cos in double.
From this we have some base rules on which to build our case. We know the total error only has to be less than the floating point implementation and we know our approximation has to reduce the cost.
So we need a way to measure the error, and a way to measure the run-time performance so we can compare.
Run-time performance is easy, we will simply run the algorithm and see how long it takes.
Error is a little more tricky. In this example we defined the error as the sum of the distance of the resulting vertex from where the most accurate implementation would place it. Ideally though, to build an approximation we want to understand where the error is coming from so we know where to change.
So let's look at the implementation again:
1 2 3 4 5 6 7 8 9 10 11 | std::array<std::pair<float, float>, numVerts> points; T theta = 0.f; T thetaStep = (T)(PI) / (T)numVerts; for (int i = 0; i < numVerts; i++) { T x = (_radius * cos(theta)) + _offset.first; T y = (_radius * sin(theta)) + _offset.second; points[i] = std::make_pair(x, y); theta += thetaStep; } |
Where could the error be introduced here? I think it would be better if we split it into individual lines per operation.
For just calculating a single 'x' position:
1 2 3 4 | T theta += thetaStep;
T cosRes= cos(theta);
T radiusScaled = cosRes * _radius;
T x = radiusScaled + _offset.first;
|
We have four operations taking place, one on each line. Let's see how the error is induced for each line step.
This step introduces error as thetaStep is stored at a fixed precision and is the product of the division of PI into the number of chunks needed to represent each step. As the number of steps gets arbitrarily large then the size of theta step gets arbitrarily smaller. This gives two problems, firstly each subsequent step will be less accurate than the last as the position on the circle is traced out, and secondly if this number is small enough that is within the rounding bounds of a floating point step then the addition to 'theta' could add 0 leading us to be unable to trace the circle or it could add more than it should leading to further inaccuracy.
Depending on the type of theta this will change the version of the function 'cos' that is called. By the cmath standard these functions are all guaranteed accurate to the unit in last place (ULP) for the type that it is working on. In this case we induce error into cosRes as any precision of real number cannot represent the infinite number of unique values between -1 and 1. Luckily, because of the standard we know that this will be on the best possible result though and the error should be relatively small. As 'cosRes' and theta share the same type there should be no rounding or error incurred by the value copy.
In this step we are multiplying two real numbers together. This should result in an arbitrary error as the resulting value is stepped down from the high precision floating point hardware back to the representation we are using. So we should get +/- the floating point step in the scale of the result.
This is the same as step 3.
Steps 2-4 are then repeated for the y component and both are cast to float to store in the vertex list. Quite a lot of potential error - depending on the type!

Represented in my pigeon math
How does this differ from our approximation? Where we simply replace the calls to sin/cos?

Not very much at all when we are considering the same type! And with the additional error from multiplication and addition which aren't guaranteed to be minimal error for the type like the sin/cos from the cmath library are.
So, when is it that we can use the approximation?
When it follows these two rules:
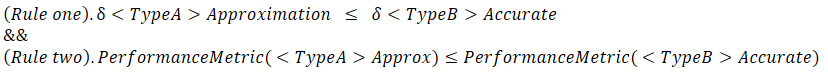
When these two rules hold true then we can replace the function without worrying.
So, for our example of better performance and accuracy we ensure that for 'double' type in the approximation function and 'float' type in the accurate implementation match both rules and we are good to go.

So that gives us this table of results for the built in standard real number types:
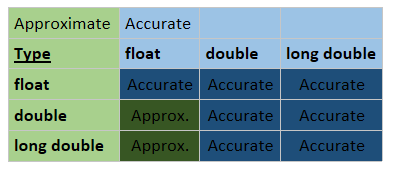
So there really is only a limited area where we meet both of these rules, but it could be a beneificial one.